
![]()


![]()
![]()

このチュートリアルでは、NGSI-LD 開発者向けの一般的な Linked Data の概念とデータモデルの基本を紹介します。目的は、 単純な相互運用可能なスマート・アグリカルチャ・ソリューションをゼロから設計および作成し、これらの概念を独自のスマート・ ソリューションに適用する方法を説明することです。
以前のチュートリアル・シリーズとは異なり、このシリーズは NGSI-LD の最初の アプローチを取るため、Linked Data の基本と NGSI-LD インターフェースへのアプリケーションの基礎を繰り返すことから 始めます。
このチュートリアルは、主にオンライン・ツールとコマンドライン・ツールに関係しています。
@context の理解¶
“Wisdom is intelligence in context.”
― Raheel Farooq, Kalam
コンピュータの読み取り可能なリンクの相互運用可能なシステムを作成するには、明確に定義されたデータ形式 (JSON-LD) を使用し、データ・エンティティとエンティティ間のリレーションシップの両方に一意の IDs (URLs または URNs) を割り当てて、データ自体からプログラムで意味を取得できるようにする必要があります。さらに、これらの一意の IDs の使用と 作成は、データ・オブジェクト自体の処理の邪魔にならないように、可能な限り引き渡す必要があります。
この相互運用性の問題を解決する試みが JSON ドメイン内で行われ、これは既存の JSON データ構造に @context 要素を追加する
ことで行われました。これにより、JSON-LD 標準が作成されました。
JSON-LD の主なポイントは、リモート・コンテキスト・ファイルと JSON-LD
@context 定義 を使用して、定義されたすべての属性に一意の長い
URNs を割り当てることができます。開発者は独自のアプリケーション内で独自の通常の短い属性名を自由に使用でき、拡張操作と
圧縮操作を適用して、URIs から優先短縮名 (preferred shortnames) に変換します。
NGSI-LD は、JSON-LD の正式に構造化された拡張サブセットです。相互運用性を促進するために、NGSI-LD API は
JSON-LD 仕様を使用して定義されます。したがって、JSON-LD 、特に @context ファイルの完全な知識は、NGSI-LD
を使用するための基礎となります。
JSON-LDとは何ですか?¶
JSON-LD は JSON の拡張であり、リンクト・データを JSON で表現するときにあいまいさを回避してデータをマシンで解析可能な
形式で構造化する標準的な方法です。これは、複数の個別のデータ・ソースから取得したときにすべてのデータ属性を簡単に
比較できるようにする方法であり、各属性の意味が異なる場合があります。たとえば、2つのデータ・エンティティに name 属性が
ある場合、同じ意味で "モノの名前" を参照しているコンピュータを特定するにはどうすればよいですか (Username または
Surname, 何かではなく)。URLs とデータモデルを使用して、属性に短い形式 (name など) と完全に指定された長い形式
(http://schema.org/name など) の両方を持たせることで曖昧さをなくします。つまり、データ構造内で共通の意味を持つ属性を
簡単に見つけることができます。
JSON-LD は @context 要素の概念を導入しており、コンピュータが残りのデータをより明確かつ詳細に解釈できるようにする
追加情報を提供します。
さらに、JSON-LD 仕様では、明確に定義された
データモデルをデータ自体に関連付ける一意の
@type を定義できます。
ビデオ: Linked Data とは?¶
![]()
上の画像をクリックして、リンクト・データの概念に関する紹介ビデオをご覧ください。
ビデオ: JSON-LD とは?¶
![]()
上の画像をクリックして、JSON-LD の背後にある基本的な概念を説明するビデオをご覧ください。
前提条件¶
Swagger¶
OpenAPI 仕様 (一般に Swagger として知られています) は、REST APIs の API 記述形式です。Swaggger 仕様では、API 全体 (NGSI-LD 自体など) を記述できますが、このチュートリアルでは、Swagger を使用してデータモデルを定義することに集中します。
API 仕様は YAML または JSON で記述できます。この形式は、学習しやすく、人間と機械の両方が読みやすくなっています。
完全な OpenAPI 仕様は GitHub にあります:
OpenAPI 3.0 Specification。
@context ファイルを生成するには、明確に定義された構造が必要になるため、これは重要です。
Docker¶
さまざまな環境で相互運用性を維持するには、Docker を使用してファイル・ジェネレータを 実行します。Docker は、それぞれの環境に分離されたさまざまなコンポーネントを可能にするコンテナ・テクノロジです。
- Windows に Docker をインストールするには、こちらの指示に 従ってください
- Mac に Docker をインストールするには、こちらの指示に従ってください
- Linux に Docker をインストールするには、こちらの指示に従ってください
Cygwin¶
簡単な bash スクリプトを使用してサービスを起動します。Windows ユーザは、cygwin を ダウンロードして、Windows 上の Linux ディストリビューションと同様のコマンドライン機能を提供する必要があります。
起動¶
ジェネレータ・ツールの実行を初期化するには以下を実行します:
./services createNGSI-LD データモデルの作成¶
FIWARE プラットフォーム内では、すべてのエンティティが物理的または概念的なオブジェクトの状態を表します。 各エンティティは、実世界に存在するオブジェクトのデジタル・ツインを提供します。
コンテキスト内の各データエンティティはユースケースによって異なりますが、再利用を促進するために、各データ・エンティティ
内の共通の構造を標準化する必要があります。FIWARE データモデル設計の基礎は変更されません。通常、各エンティティは、
id, type, 時間とともに変化するコンテキスト・データを表す一連の Property 属性、および既存のエンティティ間の
接続を表す一連の Relationship 属性で構成されます。
例を使用してこれを説明するのがおそらく最善です。基礎となるデータモデルは、さまざまなツールを使用して作成できますが、 この例では、Open API 3 標準を使用して定義された Swagger schema オブジェクトを使用します。これらの例は有効な Swagger 仕様ですが、実際には NGSI-LD API を使用してすでに定義されているため、パス (paths) と操作 (operations) での定義には関心がありません。
シナリオ¶
次のスマート・アグリカルチャのシナリオを検討します:
農家が納屋を所有していると想像してください。納屋には2つの IoT デバイスがあります。温度センサと現在納屋に 保管されている干し草の量を示す充填レベル・センサです
この例は、次のエンティティに分割できます:
- Building: 納屋
- Person: 農家
- IoT Devices:
- 温度センサ (Temperature Senor)
- 充填レベル・センサ (Filling Level Sensor)
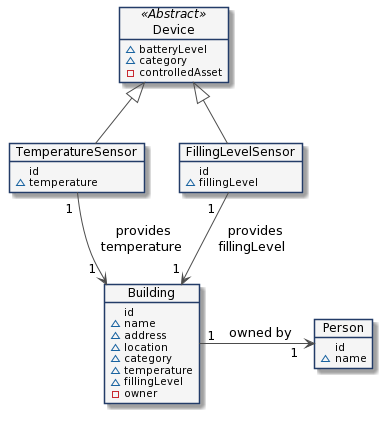
ベースライン・データモデル¶
スマート・システムを構築する場合、ゼロから開始する必要はありません。最初のステップは、システムを記述できる既存の NGSI-LD データモデルがあるかどうかを確認することです。たまたま、Building と Device の両方が既存の スマート・データモデル にあるので、 これらが私たちのニーズを満たすかどうかを確認するが可能です:
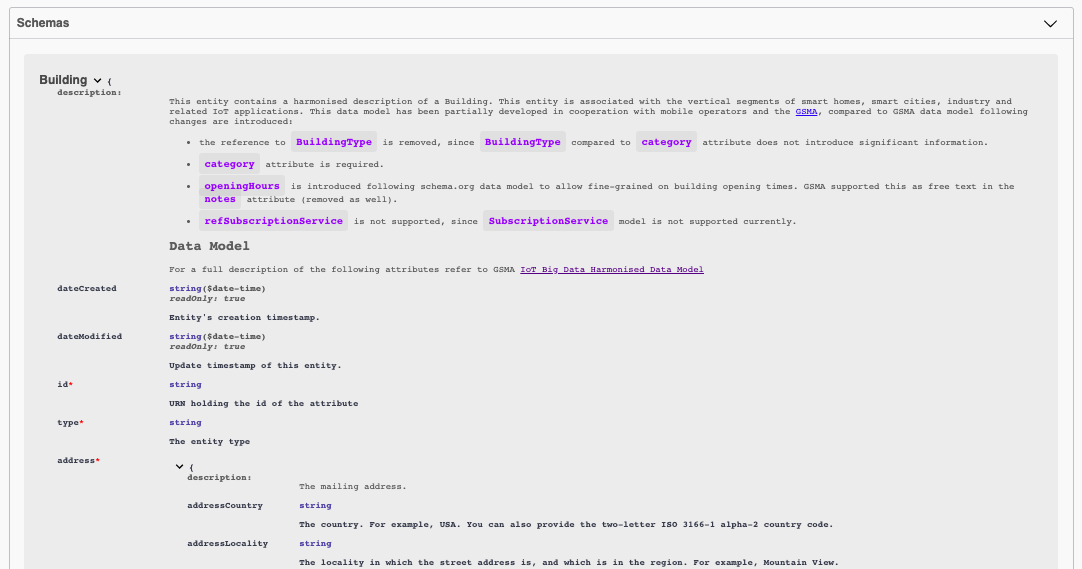
Person や Product などの多くの一般的な概念は、Schema.org によって形式化されています。 これは、インターネット上の構造化データのスキーマを宣伝するための共同コミュニティ活動です。schema.org Person は、JSON-LD スキーマを使用して記述でき、NGSI-LD データモデルとして選択できます。
- Person データモデルは こちら で検査できます
これまでに検討したモデルの定義は非常に一般的であり、実際のシステムで使用するにはさらに修正が必要になることに
注意してください。ただし、これらのモデルを相互運用性の基礎として使用すると、生成される @context ファイルが
幅広い多くのシステムで理解できるようになります。
モデルの修正¶
基本データモデルは出発点として役立ちますが、列挙値 (enumerated values) または属性の一部は冗長になり、他の必須フィールドは失われます。したがって、ベースモデルを修正して、モデリングしているシナリオに固有の適切なデジタル・ツインを作成する必要があります。
冗長なアイテムを削除¶
データモデル内の多くの属性はオプションであり、すべてのオプションがこのシナリオで有効であるとは限りません。
Building モデル内の category 属性を例にとると、これはスマート・シティやスマート・アグリカルチャなどの複数の
ドメインで役立つ60種類以上の建物を提供します。したがって、特定のオプションは使用される可能性が低いため、独自の
@context ファイルから特定のオプションを除外しても安全です。たとえば、cathedral (大聖堂) として分類された
Building は、農場で見つかる可能性は低いです。
使用するペイロードのサイズを減らすのに役立つため、特定のモデルの使用をコミットする前に膨張を削除することは論理的です。
拡張¶
Building モデルを見ると、category="barn" の Building エンティティが必要であることは明らかですが、基本の
Building モデルは temperature や fillingLevel などの追加の属性を提供しません。これらをベースの Building
に追加して、Context Broker が context (つまり、ビルディングの現在の状態) を保持できるようにする必要があります。
多くのタイプのデバイス読み取り (つまり、コンテキスト・データ属性) が SAREF オントロジ 内で事前定義されているため、これらの属性を定義する URIs をモデルを拡張の基礎として使用するのが妥当です。
temperature(https://w3id.org/saref#temperature)fillingLevel(https://w3id.org/saref#fillingLevel)
多くの測定属性は SAREF オントロジ内で定義されていますが、他のオントロジも同様に使用で
きます。たとえば、iotschema.org schema
には、 http://iotschema.org/temperature のような同等の用語 URIs が含まれていて、これもここで使用できますが、
追加のデータを @graph に追加して、Simple Knowledge Organization System terms
SKOS を使用して2つの同等性を示すことができます。
メタデータの追加¶
オントロジの一般的な階層とは対照的に NGSI-LD データモデルを設計する上での主要な目標は、可能な限り、モデルのすべての Property 属性が、実世界で具体的な何かのデジタル・ツインのコンテキスト・データを表すことです。
この定式化は、深くネストされた階層を抑制します。Building には temperature, Building には fillingLevel があり、それ以外は Relationship として定義されています。Building には owner がいて、Building エンティティを別の Person エンティティにリンクします。
ただし、プロパティの値を保持するだけでは不十分です。temperature=6 は、特定のメタデータも取得しない限り意味が
ありません。たとえば、測定値はいつ取得されましたか? どのデバイスが測定値を取得しましたか?
測定単位は何ですか? デバイスの正確さは何ですか? などです。
したがって、コンテキスト・データが理解できるようにするには、補足のメタデータ・アイテムが必要になります。 つまり、次のようなものが必要になります:
- 測定値の単位
- 測定値を提供したセンサ
- 測定値はいつ測定された
- 等々
{
"temperature": {
"type": "Property",
"value": 30,
"unitCode" : "CEL",
"providedBy": "urn:ngsi-ld:TemperatureSensor:001",
"observedAt": "2016-03-15T11:00:00.000"
}
},
{
"fillingLevel": {
"type": "Property",
"value": 0.5,
"unitCode": "P1",
"providedBy": "urn:ngsi-ld:FillingLevelSensor:001",
"observedAt" :"2016-03-15T11:00:00.000"
}
}これらの属性にはそれぞれ名前が付いているため、 @context 内での定義が必要です。幸いなことに、これらのほとんどはコア
NGSI-LD 仕様で事前定義されています。
unitCodeは、 UN/CEFACT List of measurement codes などの一般的なリストから指定されますobservedAtは、ISO 8601 形式を使用して UTC で表現された明確に定義された一時的なプロパティ (temporal property) である DateTime ですprovidedByは、NGSI-LD 仕様内の推奨例です
サブクラス化¶
新しい属性を追加してモデルを拡張するだけでなく、サブクラス化してモデルを拡張することもできます。Device モデルを
見ると、batteryLevel などのすべての IoT デバイスに役立つ共通の定義がモデルで定義されているのに対し、モデル内には、
どの読み取りが行われているかを説明する追加の属性がないことがわかります。
Device モデルを引き続き使用し、temperature と fillingLevel の両方を追加することは可能ですが、充填センサが温度を
提供することも、その逆も可能です。したがって、この場合、新しいサブクラスを作成して、温度センサを充填センサとは異なる
タイプのエンティティと見なすことができます。
Swagger を使用してベースライン・データモデルを拡張¶
初期ベースライン・データモデル¶
以下のモデルは、Smart Data Models ドメイン内で定義されています。
components:
schemas:
# これはビルディングの基本的な定義です
Building:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/building.yaml#/Building"
# これは、スマートシティおよびスマート・アグリフード・ドメイン内に
# 定義されているすべてのビルディング・カテゴリです
BuildingCategory:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/building.yaml#/Categories"
# これは IoT デバイスの基本的な定義です
Device:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/device.yaml#/Device"
# これは IoT デバイス・カテゴリの完全なリストです
DeviceCategory:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/Categories"
# これは、デバイスによって測定可能なコンテキスト属性の完全なリストです
ControlledProperties:
$ref: "https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/ControlledProperties"
# これは人の NGSI-LD 定義です
# schema.org Person は JSON-LD であるため、
# 追加の type および id 属性が必要です
Person:
allOf:
- $ref: "https://fiware.github.io/tutorials.NGSI-LD/models/ngsi-ld.yaml#/Common"
- $ref: "https://fiware.github.io/tutorials.NGSI-LD/models/schema.org.yaml#/Person"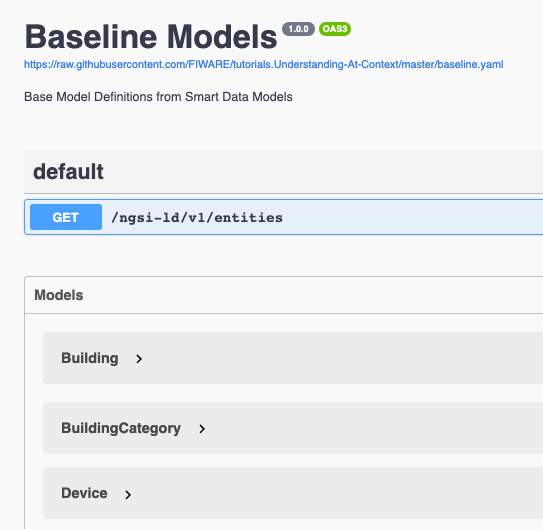
ベースライン・データモデルは、 こちら にあります。
ベースライン・データモデルのソースファイルである baseline.yaml は
こちらにあります。
更新されたデータモデル¶
- Building は、
temperatureとfillingLevelに対応するように更新する必要があります。 これらのプロパティはどちらも SAREF 用語で定義されています。
Building:
allOf:
- $ref: "https://fiware.github.io/tutorials.NGSI-LD/models/building.yaml#/Building"
properties:
temperature:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/temperature
fillingLevel:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/fillingLevel-
定義されたビルディング・カテゴリのリストは、アグリカルチャ・ドメイン内で見つかるアイテムに減らすことができます (例:
barn,cowshed,farm,farm_auxiliary,greenhouse,riding_hall,shed,stable,sty,water_tower) -
ベース・デバイスを削除して、それを拡張する2つの新しいモデルの
TemperatureSensorとFillingLevelSensorで置き換えることができます。もう一度、これらは追加の SAREF 用語を基本のDeviceクラスに追加します
TemperatureSensor:
type: object
required:
- temperature
allOf:
- $ref: https://fiware.github.io/tutorials.NGSI-LD/models/device.yaml#/Device
properties:
temperature:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/temperatureFillingLevelSensor:
type: object
required:
- FillingLevelSensor
allOf:
- $ref: https://fiware.github.io/tutorials.NGSI-LD/models/device.yaml#/Device
properties:
fillingLevel:
$ref: https://fiware.github.io/tutorials.NGSI-LD/models/saref-terms.yaml#/fillingLevel-
制御された属性のリストは、アグリカルチャ用デバイスによって測定されたものです (たとえば、
airPollution,atmosphericPressure,depth,eatingActivity,fillingLevel,humidity,location,milking,motion,movementActivity,occupancy,precipitation,pressure,soilMoisture,solarRadiation,temperature,waterConsumption,weatherConditions,weight,windDirection,windSpeed) -
その他の定義は変更されていません
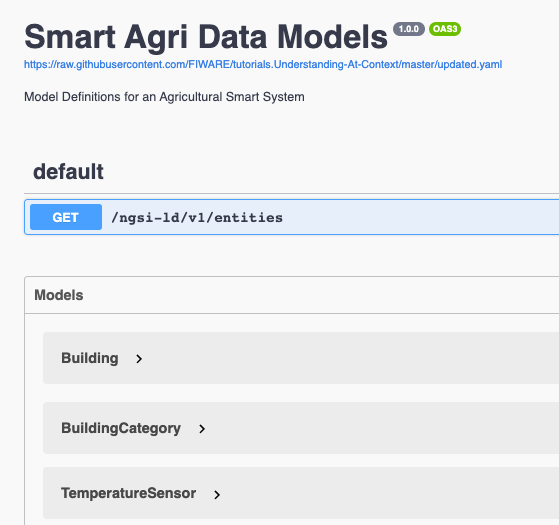
アグリカルチャ用スマート・システムの更新されたデータモデルは、 こちら で検査できます。
未加工のソースファイル agriculture.yaml は、
こちら
にあります
Swagger からの @context ファイルの自動生成¶
すべての機能するリンクト・データ・システムは、データに関連する情報を提供するために @context ファイルに依存しています。
このようなファイルを手作業で作成するのは面倒でエラーが発生しやすい手順なので、プロセスを自動化することは理にかなって
います。必要な構造は、関連する操作によって異なります。
このチュートリアルでは、アグリカルチャ用スマート・システムのデータモデル・ファイル agriculture.yaml を使用して、
他のエージェントが使用する代替案を自動生成します。
このチュートリアルをより高度な例で実行することで、より深い理解を得ることができます。このチュートリアルには、 スーパーマーケットのシナリオと同等の データモデル も追加されています。未加工の
supermarket.yamlファイルは、 こちら で利用可能です。
Swagger データモデルの検証¶
処理の前にモデルが有効であることを確認する必要があります。これは、オンラインで表示するか、 簡単な検証ツールを使用して行うことができます。
./services validate [file]ターミナル - 結果:¶
The API is valid基礎となるファイルは有効な Swagger 定義であり、 必要に応じてツールを使用して属性と列挙値を抽出できるようにします。
NGSI-LD @context ファイルを生成¶
NGSI-LD @context は、以下の定義済み URIs を保持する必要があります:
- システム内で定義されたエンティティ
types - 定義されたデータモデル内のすべての属性の名前
- データモデル内からのすべてのメタデータ属性の名前
- データモデル内で使用される定数の列挙値
NGSI-LD @context ファイルは、次のように Swagger データモデルから生成できます。
./services ngsi [file]ターミナル - 結果:¶
Creating a NGSI-LD @context file for normalized interactions datamodels.context-ngsi.jsonld created生成されたファイルを開くと、次の構造が見つかります:
{
"@context": {
"type": "@type",
"id": "@id",
"ngsi-ld": "https://uri.etsi.org/ngsi-ld/",
"fiware": "https://uri.fiware.org/ns/data-models#",
"schema": "https://schema.org/",
...etc
"Building": "fiware:Building",
"FillingLevelSensor": "fiware:FillingLevelSensor",
"Person": "fiware:Person",
"TemperatureSensor": "fiware:TemperatureSensor",
... etc
"actuator": "https://w3id.org/saref#actuator",
"additionalName": "schema:additionalName",
"address": "schema:address",
"airPollution": "https://w3id.org/saref#airPollution",
"atmosphericPressure": "https://w3id.org/saref#atmosphericPressure",
"barn": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dbarn",
"batteryLevel": "fiware:batteryLevel",
"category": "fiware:category",
"configuration": "fiware:configuration",
"conservatory": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dconservatory",
"containedInPlace": "fiware:containedInPlace",
"controlledAsset": "fiware:controlledAsset",
"controlledProperty": "fiware:controlledProperty",
"cowshed": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dcowshed",
...etc
}
}結果の @context ファイルは、NGSI-LD アプリケーションで使用できる有効な
JSON-LD コンテキスト・ファイルです。ファイルは3つの部分で構成されています:
- 標準的な用語と略語のリスト。これにより、URIs を繰り返す必要がなくなり、ファイル全体のサイズが小さくなります
- 定義された一連のエンティティ・タイプ (
Buildingなど)。これらは通常、大文字で始まります - 属性 (例:
address) と 列挙値 (例:barn) のリスト
事実上、この NGSI-LD @context は、NGSI-LD コア・コンテキスト
https://uri.etsi.org/ngsi-ld/v1/ngsi-ld-core-context-v1.3.jsonld
のコピー と組み合わせて、以下を機械的に定義します:
コンピュータが type=Building のエンティティに遭遇した場合、これは実際には
https://uri.fiware.org/ns/data-models#Building を参照します。
Building の定義から、必須の category と address があることがわかります。
コンピュータが address 属性に遭遇した場合、これは実際には https://schema.org/address を参照します。
これにはサブ属性が明確に定義されています。
コンピュータが category=barn に遭遇した場合、この category が
https://wiki.openstreetmap.org/wiki/Tag:building%3Dbarn として識別できることを確認できるはずです。
category 自体も明確に定義されていることに注意してください。
NGSI-LD の @context はすべての NGSI-LD CRUD 操作に使用され、デフォルトの normalized 形式で NGSI-LD
データを送受信するときに必要です。normalized 形式には、独自の type と value を持つ属性の構造が含まれます。
たとえば、これは normalized NGSI-LD 形式の Building です:
{
"id": "urn:ngsi-ld:Building:001",
"type": "Building",
"category": {
"type": "Property",
"value": "barn"
},
"address": {
"type": "Property",
"value": {
"streetAddress": "Großer Stern",
"addressRegion": "Berlin",
"addressLocality": "Tiergarten",
"postalCode": "10557"
}
},
"location": {
"type": "GeoProperty",
"value": {
"type": "Point",
"coordinates": [13.35, 52.5144]
}
},
"name": {
"type": "Property",
"value": "Siegessäule Barn"
},
"@context": [
"https://example.com/data-models.context-ngsild.jsonld",
"https://uri.etsi.org/ngsi-ld/v1/ngsi-ld-core-context-v1.3.jsonld"
]
}コア・コンテキスト・ファイルは、NGSI-LD API ペイロードの基本構造 (type, value, GeoJSON Point など)
を定義しますが、アプリケーション自体の generated NGSI-LD コンテキストは、ペイロード構造を定義せずにエンティティ
(Building) および attribute を定義します。
JSON-LD @context ファイルを生成¶
JSON-LD @context はスタンドアロンであり、コア・コンテキスト定義を使用せず、properties-of-properties
などのメタデータ属性定義を指定しないため、NGSI-LD @context ファイルとは異なります。これは、簡素化された
NSGI-LD Key-Value ペアのペイロードと組み合わせて使用されます。
JSON-LD には以下が必要です。
- 定義されたデータモデル内のすべての属性の名前
- データモデル内で使用される定数の列挙値
さらに、JSON-LD @context には、補足情報 (この属性は整数など) と、@graph 定義内のノード間のリレーションシップに
関する情報 (この属性は Person エンティティへのリンク) と、属性自体に関する人間が読める情報 (納屋 (barn)
は保管に使用されるアグリカルチャ・ビルディングです) が返される場合があります。
JSON-LD @context ファイルは、次のように Swagger データモデルから生成できます:
./services jsonld [file]ターミナル - 結果:¶
Creating a JSON-LD @context file for key-values interactions
datamodels.context.jsonld created生成されたファイルを開くと、次の構造が見つかります:
{
"@context": {
"type": "@type",
"id": "@id",
"ngsi-ld": "https://uri.etsi.org/ngsi-ld/",
"fiware": "https://uri.fiware.org/ns/data-models#",
"schema": "https://schema.org/",
"rdfs": "http://www.w3.org/2000/01/rdf-schema#",
"xsd": "http://www.w3.org/2001/XMLSchema#",
... etc
"Building": "fiware:Building",
"FillingLevelSensor": "fiware:FillingLevelSensor",
... etc
"actuator": "https://w3id.org/saref#actuator",
"additionalName": {
"@id": "schema:additionalName",
"@type": "xsd:string"
},
"address": "schema:address",
"airPollution": "https://w3id.org/saref#airPollution",
"atmosphericPressure": "https://w3id.org/saref#atmosphericPressure",
"barn": "https://wiki.openstreetmap.org/wiki/Tag:building%3Dbarn",
"controlledAsset": {
"@id": "fiware:controlledAsset",
"@type": "@id"
},
... etc
},
"@graph": [
...etc
{
"@id": "fiware:fillingLevel",
"@type": "ngsi-ld:Property",
"rdfs:comment": [
{
"@language": "en",
"@value": "Property related to some measurements that are characterized by a certain value that is a filling level."
}
],
"rdfs:label": [
{
"@language": "en",
"@value": "fillingLevel"
}
]
}
]
}ここでも、結果の @context ファイルは有効な JSON-LD ですが、今回は、
一般的な JSON-LD アプリケーションを理解する、すべてのアプリケーションで使用するように設計されています。
ファイルは次のように構成されています:
- 標準の用語と略語のリスト。これにより、URIs を繰り返す必要がなくなり、ファイル全体のサイズが小さくなります。 詳細については、JSON-LD 仕様のエイリアス・キーワード のセクションを参照してください
- 定義された一連のエンティティ・タイプ (
Buildingなど)。これらは通常、大文字で始まります - 属性のリスト。これらは次のように細分されます:
- ネイティブ JSON 属性として表示されるコンテキスト・データ Properties (例:
additionalName) を表す属性。 これらの属性には、データを消費するときに使用される XML スキーマの データ型を説明するために注釈が付けられます - オブジェクト (例:
address) の複雑なコンテキスト・データ Properties を表す属性。これらは前の例と同様に 残り、addressが実際にhttps://schema.org/addressを参照していることを示しています。これには、明確に 定義されたサブ属性を持ち、これらのサブ要素のネイティブタイプも定義されています - 列挙型を保持するコンテキスト・データ Properties を表す属性。例として
categoryは、"@type": "@vocab"の形式でリンク・インジケータを保持します。これらの属性が検出されると、値category="barn"は、短い名前barnを保持する文字列としてではなく、IRIhttps://wiki.openstreetmap.org/wiki/Tag:building%3Dbarnに展開できることを示します。これを実現する方法の詳細については、JSON-LD 仕様の shortening IRIs をご覧ください - コンテキスト・データを表す属性 Relationships。例
controlAsset。これらは、エンティティ間のリンクの インジケータを"@type": "@id"の形式で保持します。これは、リンク またはより正式には国際化された リソース識別子 (RFC3987 を参照) を示す構文です。 詳細については、JSON-LD 仕様内の IRIs に関するセクション を参照してください
- ネイティブ JSON 属性として表示されるコンテキスト・データ Properties (例:
- 列挙値のリスト (
barnなど)。これらは、定義された@vocab要素内に保持されている場合、受信側アプリケーションに よって容易に拡張できます
さらに、このコンテキスト・ファイルの追加のセクションは、@graph と呼ばれます。これにより、JSON-LD @context
はリンクされたデータ自体のグラフについて追加のステートメントを作成できます。たとえば、生成された @graph 要素は、
人間が読める形式の属性の説明を英語で表示します。これをさらに拡張して、各属性がどのエンティティで使用されるか、
エンティティ定義が基本定義のサブクラスであるかどうか (たとえば、TemperatureSensor は Device を拡張する)
などを示すことができます。
@graph の詳細については、名前付きグラフのセクションを
参照してください。
options=keyValues パラメータを使用して NGSI-LD リクエストが行われた場合、レスポンスは完全な NGSI-LD
オブジェクトではなく、以下のような、一般的な JSON-LD オブジェクトです:
{
"id": "urn:ngsi-ld:Building:001",
"type": "Building",
"category": "barn",
"address": {
"streetAddress": "Großer Stern",
"addressRegion": "Berlin",
"addressLocality": "Tiergarten",
"postalCode": "10557"
},
"location": {
"type": "Point",
"coordinates": [13.35, 52.5144]
},
"name": "Siegessäule Barn",
"@context": "https://example.com/data-models.context.jsonld"
}この形式は、JSON のすべてのユーザによく知られている必要があります。追加の @context 属性は、ベースの JSON
ペイロードに JSON-LD リンクト・データとして注釈を付けるために使用されるメカニズムです。
この JSON-LD ペイロードには、属性に関するメタデータが含まれていないことに注意してください。 properties of properties
や relationships of properties はありません。したがって、JSON-LD 内に移動可能なリンクを含めるには、エンティティ自体で
直接 Relationship として宣言する必要があります。例は、Device の controlledAsset 属性にあります。temperature
Property 内にある providedBy Relationship などのメタデータ属性は、NGSI-LD 構文を使用する場合にのみ通過
(traversable) できます。
ドキュメントの生成¶
@context 構文は、マシンが読み取れるように設計されています。明らかに、開発者も人間が読めるドキュメントが必要です。
NGSI-LD エンティティに関する基本的なドキュメントは、次のように Swagger データモデルから生成できます。
./services markdown [file]ターミナル - 結果:¶
Creating Documentation for the Data Models
datamodels.md created結果は、データモデルのドキュメントを保持する Markdown ファイルです。
次のステップ¶
高度な機能を追加することで、アプリケーションに複雑さを加える方法を知りたいですか? このシリーズの 他のチュートリアルを読むことで見つけることができます
License¶
MIT © 2020 FIWARE Foundation e.V.